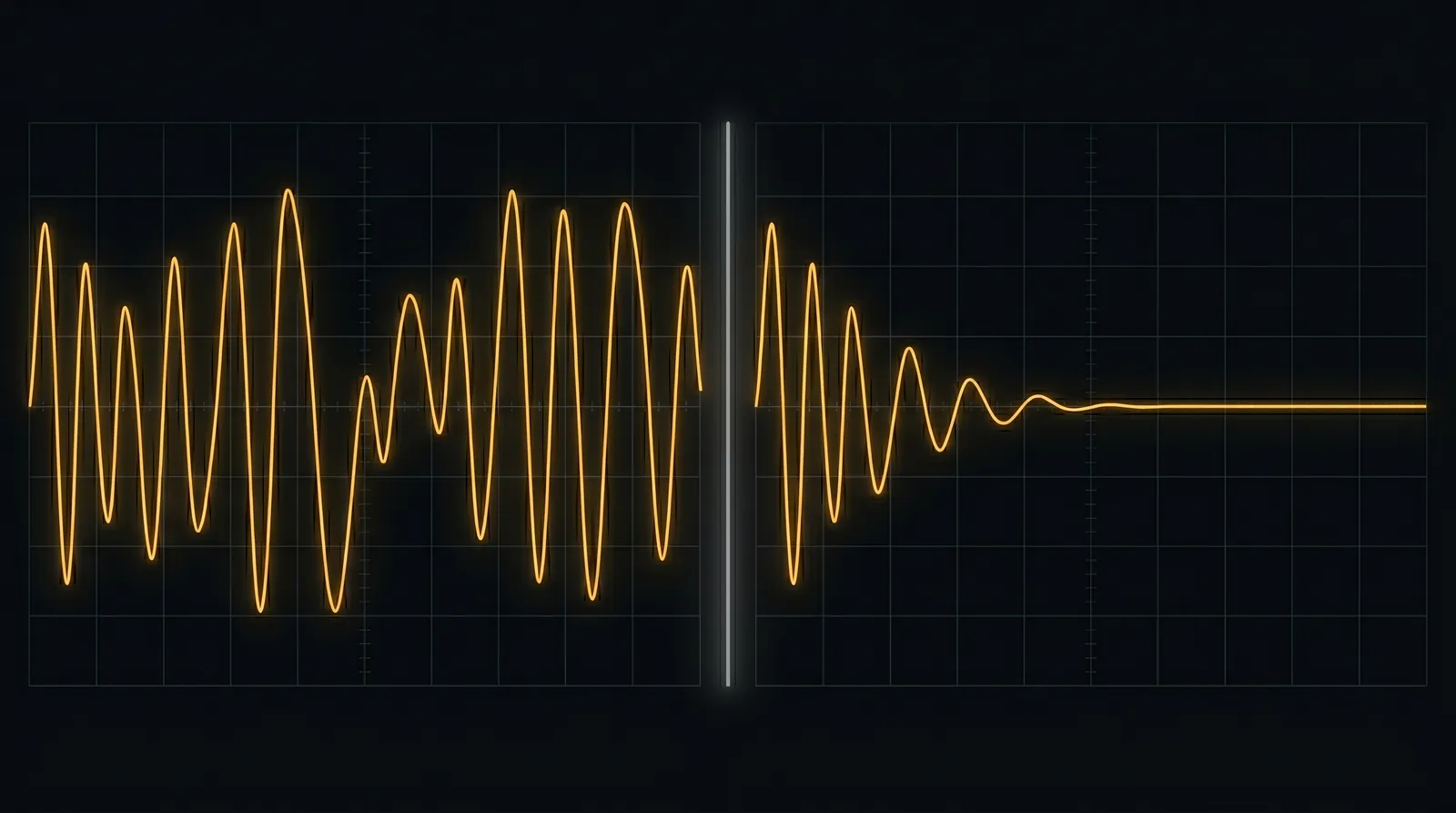
An AI agent in a verify-revise loop will keep going until something stops it. The question every team eventually asks is: what should that something be?
The default answer is max_iterations. You pick a number — usually 5, sometimes
3, occasionally 10 — and the loop runs until it either succeeds or hits the cap.
It is the most-shipped control mechanism in agentic AI, and it is a guess. The
loop has no idea whether iteration 5 is one step from done or three steps past
the point where it started making the answer worse.
When the guess costs money — and at current token prices, a runaway verify-revise loop costs real money — teams reach for tooling. This post is an honest map of what is out there. Most of it is open-source; one widely-used incumbent is not. But the license is not the line that matters. The line that matters is this: does the tool observe the loop, or does it control it?
The two questions a loop tool can answer
There are two different questions, and most tools answer only the first:
- “What did my agent just do?” — tracing, token accounting, latency, the full transcript of each step, after the fact. This is observability. It is genuinely useful and most teams need it.
- “Should this loop keep going right now?” — a decision, made during the loop, that can stop it, roll it back, or let it continue. This is control.
Observability is a dashboard you read after the run. Control is a function that runs inside the run. A team can want both, but they are not the same product, and conflating them is the most common mistake in evaluating this space.
Here is the landscape on that axis.
The observability layer
LangSmith
LangSmith is the observability and evaluation platform from the team behind LangChain. It does tracing, monitoring, and offline evaluation, and it is tightly integrated with LangChain and LangGraph.
Two things to be precise about, because they get muddled: LangSmith is proprietary — the LangChain frameworks are open-source, but LangSmith itself is a commercial product, cloud-first, with self-hosting available only on the Enterprise plan. And its job is to record and evaluate what your agents did, not to intervene mid-run.
Where it sits on the line: observe. LangSmith gives you deep visibility into each step of the loop and lets you score quality after the fact. It does not decide, while the loop is running, whether the loop should still be running.
Langfuse
Langfuse is an open-source
(MIT for the core; enterprise extras live
in a separate /ee folder) LLM engineering platform — tracing, metrics, evals,
prompt management, datasets — built on OpenTelemetry and self-hostable as a
Docker container with a Postgres backend.
Where it sits on the line: observe, and notably open-source and self-hostable, which matters for teams with data-sovereignty requirements. Langfuse and LoopGain are complementary, not competitive: Langfuse records the loop; LoopGain decides whether it should still be running. (More on the one place this gets subtle — evals — below.)
Helicone
Helicone is an open-source (Apache-2.0) AI gateway and observability platform. Its signature is the integration model: change one URL and your LLM calls route through Helicone, which logs the full request and response, tracks tokens and cost, and can apply caching, rate-limiting, routing across providers, and custom metadata before forwarding the call.
Where it sits on the line: observe, with a gateway twist. Because Helicone sits in the request path, it can gate individual calls — rate-limit them, cache them, route them. But gating a single request is not the same as deciding that a verify-revise loop has converged. A proxy sees one call at a time; it does not see the convergence trajectory across iterations, which is the signal a loop controller acts on.
The baseline that ships in every codebase
max_iterations (and its cousin, the action-hash check)
No tool required. Two patterns cover almost every loop in production today.
The cap — LangGraph spells it recursion_limit, most hand-rolled loops spell it
max_iterations, but it is the same idea:
for i in range(max_iterations): # the cap
result = agent.step()
if result.done:
break
and the slightly smarter “stop if nothing changed”:
seen = set()
while True:
result = agent.step()
h = hash(result.action) # the action-hash check
if h in seen: # exact repeat → bail
break
seen.add(h)
These are not strawmen. They are the real, reasonable, everywhere-deployed baseline, and they fail in two specific ways:
- The cap is a guess.
max_iterations=5stops a loop that needed 3 (wasting two iterations) and a loop that needed 8 (returning a worse answer than it had at iteration 4). One number cannot be right for both. - The action-hash check only catches exact repetition. A loop that is oscillating between two near-but-not-identical answers, or slowly degrading, hashes to a new value every time and runs to the cap.
This is the gap the control layer exists to close.
The control layer — where LoopGain sits
LoopGain answers question 2. It is an open-source (Apache-2.0) Python library that measures, every iteration, whether the loop is actually converging — and acts on that measurement while the loop is still running.
You give LoopGain an error signal each iteration — whatever “wrong” means for your loop: the number of failing tests, the count of schema violations, an LLM-judge’s distance from the target, a lint-error count. LoopGain doesn’t define correctness for you; you hand it the number, and it watches that number’s trajectory.
The underlying quantity is loop gain, written , borrowed from the Barkhausen stability criterion in control engineering: the factor by which the error changes from one iteration to the next. means each pass shrinks the error; means it holds or grows — the signature of an agent talking itself out of a correct answer.
A single step is noisy, though, so LoopGain doesn’t react to one ratio. It looks
at the trajectory of your error signal across the whole loop. Working in log
space — where a geometric trend becomes a straight line — it fits the
trend across iterations, runs a significance test to check the trend is real
rather than chance, and measures how much the error is oscillating around it. From
those, it classifies the loop’s current state — one of five trajectory bands,
plus the TARGET_MET short-circuit — and acts on it:
| State | What it means | Action |
|---|---|---|
TARGET_MET | error hit your target | stop, keep the answer |
FAST_CONVERGE | error collapsed fast, still dropping | continue |
CONVERGING | error trending down, significantly | continue |
STALLING | trend has flattened | stop and keep best-so-far once it persists |
OSCILLATING | bouncing around, not improving | stop, roll back to best-so-far |
DIVERGING | error trending up | stop, roll back to best-so-far |
TARGET_MET is the “done” stop — a short-circuit that fires when your error
signal hits its target. FAST_CONVERGE is not a stop: the error has dropped
sharply but isn’t at target yet, so the loop keeps going. The loop stops early
when the trajectory goes bad (OSCILLATING / DIVERGING) or flat (STALLING).
The integration wraps your existing loop. should_continue() is the new guard,
observe() records each iteration’s error, and the best-so-far answer is there if
the loop degraded:
from loopgain import LoopGain
lg = LoopGain(max_iterations=20) # the cap is now a backstop, not the plan
while lg.should_continue():
output = agent.step() # your verify-revise step
errors = verify(output) # the error signal: failing tests, etc.
lg.observe(errors, output) # measure Aβ; updates the loop's state
answer = lg.result.best_output # best-so-far — even if the last pass got worse
should_continue() returns False the moment LoopGain detects a terminal state —
converged, stalled, oscillating, diverging, or the max_iterations backstop. max_iterations
does not disappear; it becomes the backstop instead of the primary control. The
loop now stops when it has converged, not when it has run out of retries — and
lg.result.best_output gives you the best answer the loop ever produced, not
whatever it happened to land on at the end.
“But I can do that with an eval”
The fair objection. Langfuse and Helicone both have evals, and you could wire an LLM-as-judge eval into your loop and stop when it crosses a threshold. People do.
The difference is what you are measuring and what you have to build. An eval gives you an absolute quality score and leaves you to write the stopping logic — pick a threshold, handle the case where quality goes up then down, remember the best-so-far answer, decide what “no longer improving” means. LoopGain measures the dynamics of the loop directly — the trend of the error across iterations and whether it’s statistically real — which is what actually tells you whether more iterations will help, and ships the stop + rollback as the product. One is a metric you build a controller around; the other is the controller.
The worked arithmetic
The reason this is worth a library and not a shrug: the waste is measurable.
In our public benchmark — 2,000
paired real-API trials across four conditions — a fixed max_iterations=20 baseline cost
$27.05 in total tokens. The same workloads under LoopGain cost $1.94: a
92.8% cost reduction, or $25.11 saved across the run, because most loops
had converged long before iteration 20 and LoopGain stopped them there. Median
wall-clock dropped from 30.9s to 2.1s — about 15× faster — for the same reason:
you stop paying for iterations that are no longer improving the answer.
Quality held. On natural-distribution workloads a blind judge preferred LoopGain’s output to the run-to-cap baseline 50–63% of the time (i.e. preserved it), and on workloads engineered to degrade — where running to the cap actively makes the answer worse — it preferred LoopGain 92–95% of the time, because the rollback caught the degradation. The full protocol, the pre-registered floor we missed, and the raw data are public.
Where LoopGain doesn’t help
It only does anything for iterative loops. A single-pass agent — one model call, no revise step — has no trajectory to read, so there is nothing to control. You also have to be able to produce an error signal each iteration; if you cannot say how wrong an output is, LoopGain cannot tell whether the loop is improving. And it needs a few iterations to estimate the trend — on a loop that finishes in one or two steps, the cap is doing the work, not LoopGain. The benchmark above is real, but it is our workloads; how much you save depends on how noisy your error signal is and how often your loops actually run long. If your loops are already short and cheap, you do not need this.
So which tool do you actually want?
The honest answer, and the whole point of drawing the line:
- If your question is “what did my agents do?” — you want an observability tool. Langfuse or Helicone if you want open-source and self-hostable; LangSmith if you are already in the LangChain ecosystem and want evals next to your traces (and are fine with a proprietary, cloud-first tool).
- If your question is “should this loop still be running?” — that is control, and observability tools do not answer it. That is where LoopGain lives.
- Most teams running real agent loops eventually want both: LoopGain to decide, an observability tool to record what it decided. They sit at different layers and compose cleanly.
LoopGain is pip install loopgain, Apache-2.0, with adapters for LangGraph,
CrewAI, AutoGen, LangChain, OpenAI Agents, and the Claude Agent SDK — plus a raw
API for anything else. The benchmark,
the protocol, and the data are open.
FAQ
Is LangSmith open source?
No. LangSmith is a proprietary, cloud-first product from the LangChain team; self-hosting is available only on the Enterprise plan. The LangChain and LangGraph frameworks are open-source, but LangSmith itself is not. Langfuse (MIT) and Helicone (Apache-2.0) are the open-source, self-hostable observability options.
What’s the difference between AI agent observability and loop control?
Observability tools (LangSmith, Langfuse, Helicone) record and evaluate what an agent loop did, after the fact — traces, token cost, quality scores. Loop control (LoopGain) decides, while the loop is still running, whether it should keep going, stop, or roll back to its best answer. Observability is a dashboard you read after the run; control is a function that runs inside the run. Most teams running real loops want both.
Can’t I just lower max_iterations?
No single cap is right for every input. max_iterations=5 stops a loop that
finished at iteration 3 (wasting two passes) and returns a degraded answer for one
that peaked at iteration 4 of 8. LoopGain measures each loop’s actual convergence
(loop gain, Aβ) and stops when that loop has converged or started to degrade —
instead of guessing one number for all of them.
What is loop gain (Aβ) for an AI agent loop?
Loop gain, written Aβ, is the factor by which the error changes from one
iteration to the next. Aβ < 1 means the loop is converging (error shrinking);
Aβ ≥ 1 means it’s stalling or diverging. From an error signal you supply
(failing tests, schema violations, a judge score), LoopGain estimates the
Aβ trend across the loop — fitting it in log space and testing that the trend
is statistically real — and stops the loop when that trajectory shows it has
converged or begun to degrade. The term comes from the Barkhausen stability
criterion in control engineering.
Do I need both LoopGain and an observability tool?
They compose rather than compete. LoopGain controls the loop at runtime (stop + best-so-far rollback) and runs in-process as an Apache-2.0 library; an observability tool records what happened for later analysis. Use LoopGain to keep loops from running too long or degrading, and pair it with Langfuse, Helicone, or LangSmith if you also want tracing and evals.
LoopGain is an open-source library that stops AI agent loops when they’ve converged and rolls back when they’re degrading — so you stop paying to iterate past a good answer. Tool details above were verified against each project’s own documentation in May 2026; capabilities change, so check the primary sources if you are making a decision on them.