cumulative ≤ 10%
Error has dropped to a tenth of where it started, or better. The reviser is operating well inside its competence; the only correct move is to stay out of the way.


When an agent keeps checking and revising its own work, it often spins on a problem it can't solve — or talks itself into an answer worse than one it already had. LoopGain watches the loop as it runs, stops it at the right iteration, and keeps the best version, not the last.
max_iter=20
$27.05 → $1.94 · $25.11 saved across the bench
see the cost breakdown →
02 · latency
~15×
faster wall-clock per trial
30.9s → 2.1s median per trial
see the latency data →
03 · quality
0.678
aggregate judge preference for LoopGain vs max_iter=20
1,800 cross-vendor pairwise comparisons; CIs in writeup
see the quality findings →
Search any agent codebase for max_iterations. You'll find 5.
Sometimes 10. Nobody can defend the number, because no one has a principled way to pick it.
It's the universal pre-crash hack. It fires too early on a loop that was three iterations from converging, or too late on one that started diverging in iteration two — the model is now five rewrites deep into a hallucination and the bill is real.
we just set it to five and hope.
three failure modes a static cap can't tell apart · what the trajectory classifier resolves in one state
Each iteration produces an error signal. LoopGain reads four features off the full error trajectory — cumulative reduction, trend slope, trend significance, and oscillation magnitude — and routes the loop into one of five named states. Two say keep going, three say stop. The state itself is the decision.
Error has dropped to a tenth of where it started, or better. The reviser is operating well inside its competence; the only correct move is to stay out of the way.
Healthy progress. A statistically significant downward trend, or at least a halving of cumulative error. Most well-tuned agent loops live here.
No significant slope and no detectable oscillation — the loop is doing something, but it's not making progress. After two consecutive readings the library stops and returns the best-so-far. Usually a reviser-prompt plateau.
The trajectory's detrended residuals are too large to be noise but the slope is flat — the model is undoing its own last revision. Rollback. Stop.
A statistically significant upward trend with at least 10% cumulative growth. Each iteration is making the output strictly worse. The longer it runs, the more money you light on fire. Rollback. Stop.
Four trajectory features, one of five named states out. The whole library is a few hundred lines around this classifier. The result is a stop decision your model never had to make.
Two calls inside your loop: should_continue() to gate it, observe() to feed it the latest error. Read lg.result when it exits. That's the whole integration.
Framework adapters wrap the same primitive — pick the one that matches your stack, or stay raw.
# amber stripe = the lines you add or change. everything else is your existing loop.
from loopgain import LoopGainlg = LoopGain(target_error=0.1, max_iterations=20)
while lg.should_continue(): errors = your_verifier(output) # your existing code
lg.observe(errors, output=output) output = your_refiner(output, errors) # your existing code
result = lg.result# result.outcome → "converged" · "oscillating" · "diverged" · "stalled" · "max_iterations"
# result.best_output → argmin(E(n)) — the actual best draft, not the last# result.savings_vs_fixed_cap → iterations you didn't burn vs a fixed cap
# amber stripe = the lines you add or change. pip install 'loopgain[langgraph]'
from loopgain import LoopGainfrom loopgain.integrations import LangGraphAdapter
graph = build_verify_revise_graph().compile()
lg = LoopGain(target_error=0.1, max_iterations=20)adapter = LangGraphAdapter(
lg=lg,
error_fn=lambda update: len(update.get("verifier", {}).get("errors", [])),
)final_state = adapter.run(graph, {"draft": initial})
# adapter.stream() yields each step if you want the full trace.
# adapter.arun() / adapter.astream() are the async counterparts.
# amber stripe = the lines you add or change. pip install 'loopgain[crewai]'
from loopgain import LoopGainfrom loopgain.integrations import CrewAIAdapter
crew = Crew(agents=[writer_agent, verifier_agent], tasks=[task])
lg = LoopGain(target_error=0.1, max_iterations=20)adapter = CrewAIAdapter(
lg=lg,
task_error_fn=lambda task_output: count_failed_checks(task_output.raw),
)with adapter: # installs callbacks; uninstalls on exit adapter.install(crew) result = crew.kickoff()
# Observations land on `lg.result` — same shape as the raw API.
# Existing callbacks you had installed are chained, not clobbered.
# amber stripe = the lines you add or change. pip install 'loopgain[autogen]'
from autogen_agentchat.teams import RoundRobinGroupChat
from loopgain import LoopGainfrom loopgain.integrations import AutoGenAdapter
team = RoundRobinGroupChat(participants=[generator, verifier])
lg = LoopGain(target_error=0.1, max_iterations=20)adapter = AutoGenAdapter(
lg=lg,
error_fn=lambda msg: parse_verifier_score(msg.content),
observe_sources={"verifier"}, # only verifier drives observe()
)result = await adapter.run(team, task="draft, verify, revise")
# Legacy v0.2 ConversableAgent.initiate_chat is not supported.
# amber stripe = the lines you add or change. pip install 'loopgain[langchain]'
from langchain.agents import create_agent
from loopgain import LoopGainfrom loopgain.integrations import LangChainAdapter
agent = create_agent(model="gpt-5-nano", tools=[get_weather])
lg = LoopGain(target_error=0.0, max_iterations=20)adapter = LangChainAdapter(
lg=lg,
error_fn=lambda chunk: count_unresolved_tool_calls(chunk),
)final = adapter.run(
agent,
{"messages": [{"role": "user", "content": prompt}]},
stream_mode="updates", version="v2",
)
# Duck-typed: also drives the legacy AgentExecutor.stream() shape.
# amber stripe = the lines you add or change. pip install 'loopgain[openai-agents]'
from agents import Agent
from loopgain import LoopGainfrom loopgain.integrations import OpenAIAgentsAdapter
agent = Agent(name="Refiner", instructions="...", tools=[verify_tool])
lg = LoopGain(target_error=0.0, max_iterations=20)adapter = OpenAIAgentsAdapter(
lg=lg,
error_fn=lambda event: parse_verifier_failures(event),
)result = await adapter.run(agent, input="Fix the bug.")
# Defaults to run_item_stream_event; cancels the stream at terminal state.
# adapter.run_sync(...) wraps the async path with asyncio.run.
# amber stripe = the lines you add or change. pip install 'loopgain[claude-agent-sdk]'
from claude_agent_sdk import ClaudeAgentOptions, TextBlock
from loopgain import LoopGainfrom loopgain.integrations import ClaudeAgentSDKAdapter
lg = LoopGain(target_error=0.0, max_iterations=20)adapter = ClaudeAgentSDKAdapter(
lg=lg,
error_fn=lambda msg: count_fail_markers(msg),
)result = await adapter.run(
prompt="Write a haiku about feedback loops.",
options=ClaudeAgentOptions(system_prompt="Self-verify each draft."),
)
# Default filter: only AssistantMessage reaches error_fn.
# Also accepts message_iterator=client.receive_messages() for ClaudeSDKClient.
The library ships with seven examples — each runs the same loop twice, once with the universal max_iterations=N hack and once with LoopGain, and prints the comparison. Two commands, real Anthropic API calls, the Saved number is what you actually pay.
01 install with the examples extra
pip install 'loopgain[examples]'
copy
02 run the stuck-loop demo
python examples/05_unsolvable_stalls.py
copy
Example 05 hands Claude a spec that's impossible by construction, so the error never reaches 0 — the loop makes no progress, attempt after attempt. A fixed max_iterations=10 keeps paying for all ten, and a naive if error == 0: break would never fire. LoopGain reads the flat trajectory as STALLING and stops at iter 3 — 70% less spend on a loop that was never going to win. The chart up top catches a loop going wrong; this catches one going nowhere.
All seven examples → real Claude loops · verified output across TARGET_MET · STALLING · DIVERGING
─── BASELINE: no LoopGain, fixed cap = 10 ───
iter 1 error=1 (forbidden tokens used)
iter 2 error=1 (forbidden tokens used)
…
iter 10 error=1 (no coroutine driver)
→ kept LAST output (error=1).
─── WITH LOOPGAIN: target_error=None, max_iterations=10 ───
iter 1 error=1.00 state=FAST_CONVERGE
iter 2 error=1.00 state=STALLING
iter 3 error=1.00 state=STALLING → stop
┌─ COMPARISON ─────────────────────────────────
│ Baseline: 10 iters, error 1, kept LAST
│ LoopGain: 3 iters, error 1, stopped on STALLING
│ Saved: 7 iterations (70%) of API spend
└──────────────────────────────────────────────
outcome: stalled
Four trajectory features per loop, one of five named states out. Two say keep going, three say stop. The library never asks you to interpret a number — the state is the decision.
Every iteration's output is held in a rolling buffer paired with its error score, with argmin(E(n)) tracked. On rollback you don't get the latest draft — you get the actually-best one the loop produced.
Every run reports savings_vs_fixed_cap — the exact iterations you didn't burn versus a fixed cap. The dashboard rolls the fleet total up in the Waste Report and prices it at your cost-per-iteration, turning iterations-not-wasted into a dollar figure.
LangGraph .stream() step. CrewAI callback. AutoGen run_stream(). LangChain create_agent / AgentExecutor stream. OpenAI Agents SDK stream_events(). Claude Agent SDK query(). Raw LoopGain class if you have your own runner. All six adapters wrap the same core.
Off by default. If you turn it on, we receive band transitions and gain readings — never your prompts or outputs. The contract is in the README and the receiver is open-source.
The core wheel has zero runtime deps. Framework adapters are pip extras — pip install 'loopgain[langgraph]', [crewai], [autogen], [langchain], [openai-agents], [claude-agent-sdk], or [all]. Your service tree stays clean.
LangSmith, Langfuse, Helicone and Phoenix are tracing and evaluation tools — they record what your agent did so you can read it back later. That work is genuinely useful, and LoopGain runs happily alongside any of them. But none of them sits inside the running loop and decides when it's done. That is the gap LoopGain fills: it reads the error trajectory in real time and returns a stop-or-rollback decision while the loop is still running.
| Tool | Operates at | License | Framework-agnostic | Real-time loop control |
|---|---|---|---|---|
| LoopGain | the loop — convergence state | Apache-2.0 (OSI) | yes · 6 adapters + raw API | stops & rolls back to best-so-far |
| LangSmith | requests & traces | closed · self-host on Enterprise only | SDKs, but LangChain / LangGraph-first | observe only |
| Langfuse | requests & traces | MIT (OSI) | yes | observe only |
| Helicone | requests · proxy | Apache-2.0 (OSI) | yes | observe only |
| Arize Phoenix | requests & traces | Elastic v2 · source-available, not OSI | yes · OpenTelemetry | observe only |
| Braintrust | offline evals & experiments | closed · proxy is OSS, platform isn't | yes | observe only |
max_iter=N |
the loop — fixed cap | — | yes | static guess · no measurement |
A fast-moving category — competitor facts verified June 2026. LoopGain is control, not tracing: run it next to whichever observability tool you already use.
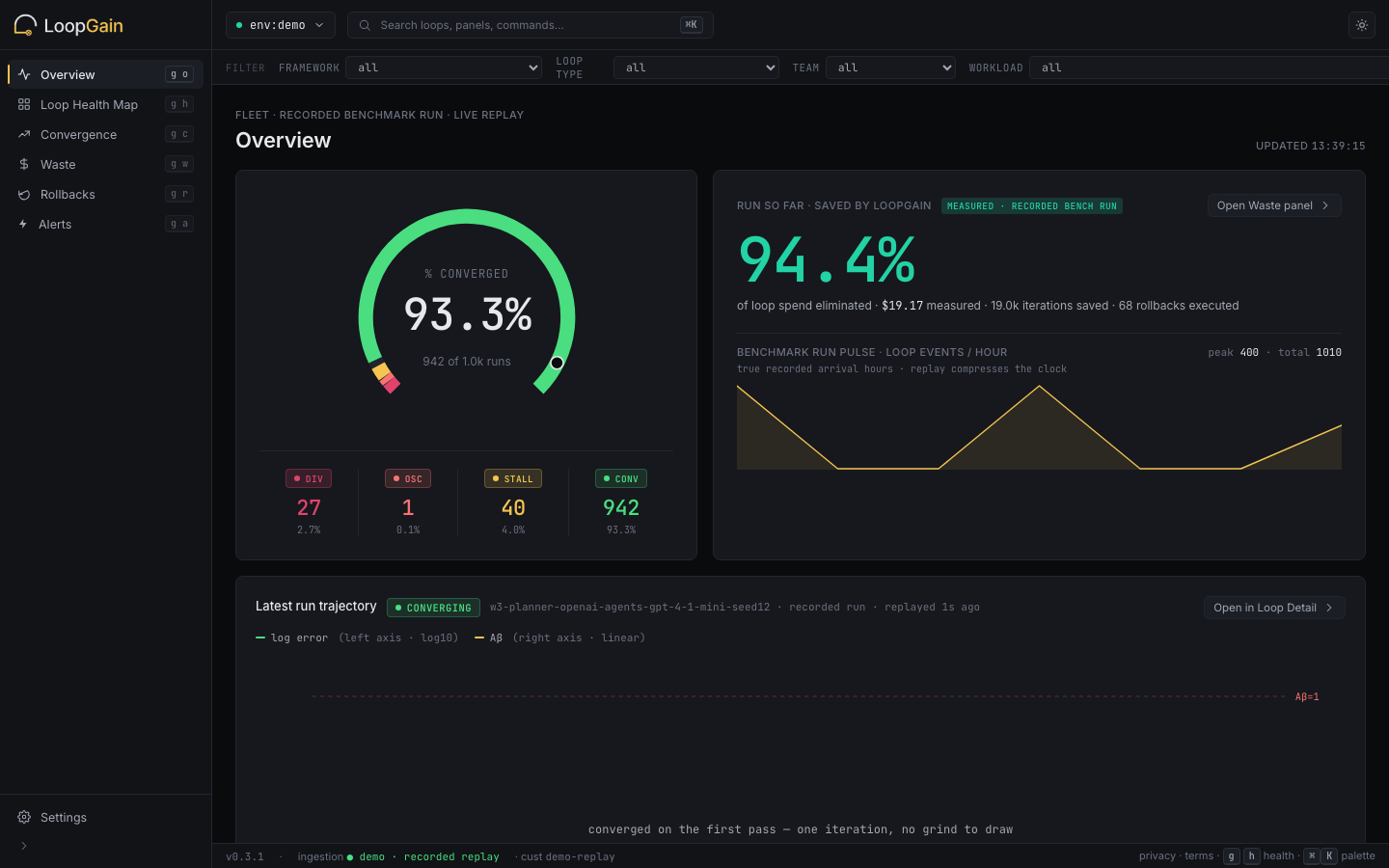
Six panels over your real fleet: Overview, Loop Health Map, Convergence, Waste Report, Rollback Log, and Alerts on band transitions. Below is the demo itself — a live replay of the real 2,000-run public benchmark, picked up 1,000 runs before the end. Every figure is the bench tenant's own measured state, accruing as recorded runs land about once a second; nothing is scaled or simulated. Open it and poke at every panel without integrating first.
Apache-2.0 across the stack — library, receiver, dashboard. Self-host the whole thing, or use the hosted dashboard free as one person. Team and Enterprise are what you buy when more than one person needs the same view — each going further on retention, alerting, security, and compliance.
pip install loopgain
copy
The Barkhausen criterion is the foundational stability result in feedback engineering. It says: if the loop gain is greater than one, your system oscillates or diverges. If it's less than one, it converges. Every amplifier, every closed-loop electronic system since has had to satisfy it.
An LLM agent loop is a feedback loop. Output in, scored output out, fed back as the next input. The math doesn't care that the gain element is a transformer instead of a vacuum tube. Apply Barkhausen and you get the same answer you'd get in any other control system: this loop is stable, this one isn't, stop the unstable one before it costs you anything else.