

LoopGain Benchmark
2,000 paired real-API trials. 10 cells across 6 framework adapters. Methodology pre-registered and locked 2026-05-21 — before any of the confirmatory data was collected.
Re-validated on loopgain v0.4.0 (carried unchanged into the current release); results landed 2026-06-03. The v0.4.0 classifier corrects a trajectory-label bug — a stuck loop now reads as STALLING, not OSCILLATING — and the corrected verdict terminates one iteration later, so the cost headline moved 93.5%→92.8%. Full re-validation note in the bench RESULTS.md.
The numbers
Across the full registered run — 10 cells × n=200 paired trials = 8,000 loop runs + 1,800 pairwise judge comparisons:
| max_iter=5 | max_iter=10 | max_iter=20 | LoopGain | |
|---|---|---|---|---|
| Total API spend | $6.83 | $13.65 | $27.05 | $1.94 |
| Median wall-clock per trial | 7.2s | 14.8s | 30.9s | 2.1s |
Implied savings vs max_iter=20 |
— | — | — | 92.8% cost / 93.3% time |
Absolute wall-clock is environment- and concurrency-dependent and isn't a headline metric — this re-run ran on a less-contended machine than the 0.2.0 run, so the seconds are lower. The ~15× LG-vs-max_iter=20 ratio is the stable claim; cost ratios are stable to ~1 pp run-to-run.
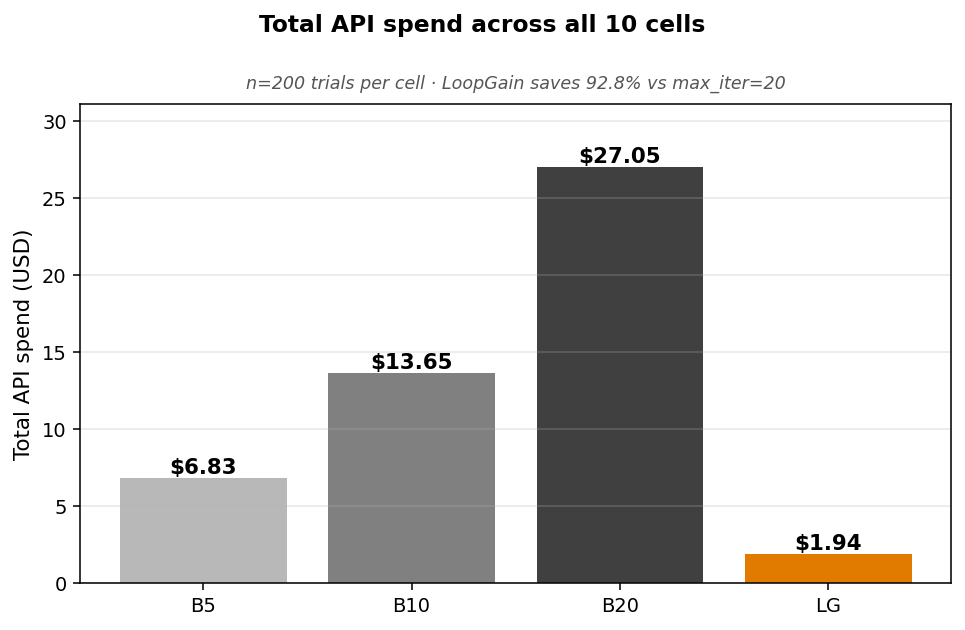
- 92.8% cost reduction vs
max_iter=20 - ~15× wall-clock speedup (30.9s → 2.1s median per trial)
- Quality preserved on natural-distribution workloads (W1–W2 judge winrate 0.55–0.63 with CI excluding null on most cells; W3 cells tie-dominated as preservation-by-construction since both LoopGain and
max_iter=20produce the same correct tool call ~90% of the time) - Quality improved on engineered-failure workloads (W5 winrate 0.92–0.95 across three adapters via best-so-far rollback)
- Aggregate weighted-average pairwise preference for LoopGain across 1,800 judge comparisons: 0.678 — over two-thirds
- Zero of six kill criteria fired
See it live
The bench tenant's 2,000 trials are visible in the actual product dashboard — the same UI a customer would see, populated with the canonical benchmark data. Read-only public view; sign up free to instrument your own loops.
Honest disclosures
One pre-registered floor was missed without firing a kill criterion. It's surfaced in the writeup:
- H-FRAMEWORK-PARITY W2 spread: 5.5 pp observed vs ≤5 pp predicted (kill threshold: >15 pp)
Under the original 0.2.0 run, H-EARLYWARN missed at 2 iterations and the widest parity spread was W1 at 5.8 pp; the corrected 0.4.0 classifier flags STALLING earlier, so median lead time now meets the ≥3-iteration floor and the widest spread moved to W2 at 5.5 pp.
Seven pre-data amendments to the methodology are preserved in BENCH_PROTOCOL.md with their full rationale. Predicted floors and kill criteria were never changed once data started landing.
The bench harness itself had two non-trivial bugs caught and fixed during the run (signal-handling under concurrency; thread-pool shutdown semantics) — both forensics documented honestly in LESSONS.md. The data here is from the post-fix, n=200, tripwire-clean run.
Reproduce it yourself
The bench, its methodology, the raw data (9.4 MB of JSONL across 10 cells + 9 judge runs), all six analysis charts, the engineering forensics, and all seven pre-data amendments are public:
github.com/loopgain-ai/loopgain-bench
$ git clone https://github.com/loopgain-ai/loopgain-bench $ cd loopgain-bench $ make install-dev $ make bench # ~$50, ~4-8h on a single Mac $ make judge # ~$1-2 $ make analyze # six tables + six charts
Try LoopGain
pip install loopgain — or pip install 'loopgain[<your framework>]' for adapter extras (LangGraph, CrewAI, AutoGen, LangChain, OpenAI Agents SDK, Claude Agent SDK).
pip install loopgain
copy
3 design-partner slots open for the next 30 days. Free 30-day pilot, direct founder support. Email hello@loopgain.ai.